乔宇 中国科学院深圳先进技术研究院集成所副所长
以下内容为乔宇在中科院SELF讲坛演讲实录:
我叫乔宇,来自中国科学院深圳先进技术研究院。今天我想跟大家分享的是“给机器装上慧眼,看懂世界”。

我们都有这样的经历,当我们去看一个几个月的宝宝的时候,宝宝会情不自主地盯着我们,甚至冲我们笑一笑。为什么呢?研究发现,即使是几个月大的孩子,都具备识别人脸、判别人脸的能力。

当我们看到美丽的湖光山色时,我们可能情不自禁地感叹自然的壮美,感觉心旷神怡、心情大好。

再看一张好像没有趣味的图片,大家能不能从这张图片中看出来点什么?我给大家一点提示,圈里面是不是好像有一条狗?事实上,我们每个人都有一种与生俱来的视觉能力,就是通过眼睛去感知周围的环境、欣赏美景,去阅读书籍、理解世界。
眼睛和后面的视觉系统是我们人类最为复杂,也最为重要的器官之一。人类获得的70%的信息来自于眼睛,我们的眼底有上亿个神经元的细胞用于感知、进行光电作用,人脑中涉及视觉信息处理的细胞达到数百亿。我研究的目的就是让计算机像人一样能够看懂世界、理解世界。

计算机视觉是人工智能的核心领域之一,也被认为是推动当前社会发展、经济进步的重要革命性技术。它的应用领域非常广泛,包括人脸识别、自动驾驶、安防监控、工业检测、医学影像、照片美化等等。
为什么我们会关注计算机视觉技术?事实上人类社会现在正在进入视觉信息的大数据时代,我们日常会使用微信,微信上每天上传的图片、分享的数频达到数十亿次。另外一个很大的视觉信息来源是监控摄像头。据估计,在我们国家已经安装了超过1.7亿个摄像头,每分每秒都会有大量数据的产生。

目前我们的系统已经可以实现很好的采集,因为摄像头已经很便宜了,一个监控摄像头几百块钱,装在手机上的千万像素级的摄像头,大概只要几美元。也可以实现很好的存储,即使用一个手机,我们也可以存储几千张甚至上万张照片。对于传输,我们现在用5G网络,4G网络都可以很好地看实时的视频,5G网络自然可以做到更好的传输。
现在技术最大的瓶颈就在于机器不能够像人一样去理解、识别图像的内容,所以很多的视频网站才需要雇用很多人来过滤一些不合法的视频。而对于监控视频来讲,一旦有案件发生,警察同志都要日夜兼程地阅览大量监控视频。
在这个背景下面,利用计算机视觉技术让计算机能够理解图片、识别视频就显得尤为重要。在这个背景下,我们科学院的前副院长谭铁牛院士提出“图像视频、大数据是人工智能突破口,是信息产业的增长点”。
很多人就会问,理解图片、视频有什么难的?我们家小孩都可以做得很好,下面我就想通过一个三岁的小孩就可以做好的例子跟大家分享一下,为什么让计算机理解图片非常难?

这个任务就是识别猫,给出一张图片,我们判断这张图片中有没有猫。我们知道有各种类型的猫,有白猫、灰猫、黑猫。

猫可能站着、趴着、躺着,有些猫要跳,还有各种各样可爱的动作。

图片中可能还不止一只猫,这些猫之间可能还有一些遮挡、交互。
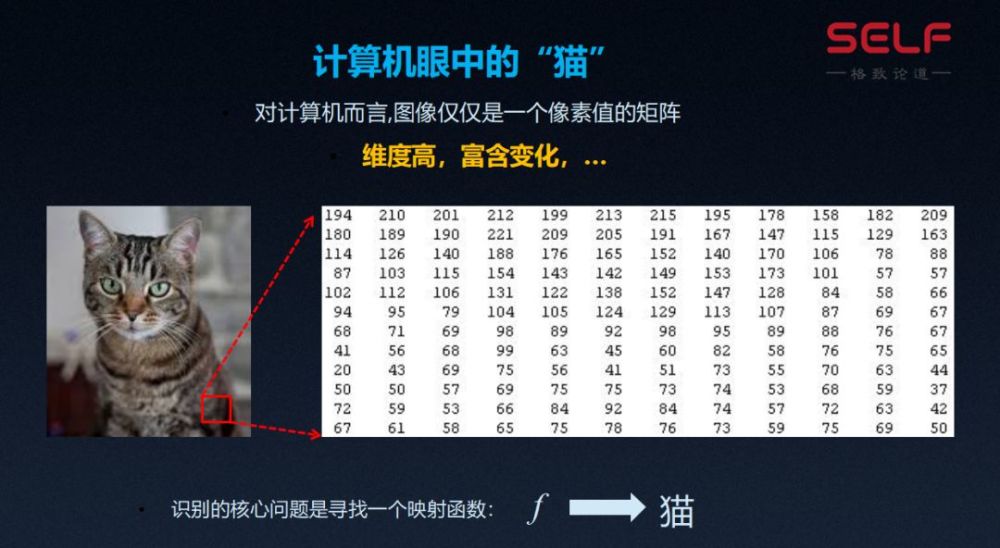
很多小朋友会倾向于把这些也归为猫,那对计算机来讲,一张猫的图片是什么呢?
我们知道计算机是把图片中每个像素的RGB,也就是红、绿、蓝三个通道的值存储下来。对计算机来讲,一张图片就是一个巨大的像素的矩阵,每个点的位置是这个点的色彩值。那么我们要解决的核心问题就是要找到一个映射函数,把一张图片映射到猫的概念,这个问题的挑战就在于我们输入的维度很高,可能上千万维,里面又包含着色彩的变化、姿态的变化、光照的变化、猫的数目的变化等等非常复杂的变化,这些就是我们要解决的挑战。
最早人们在想怎么教计算机识别猫的时候,觉得应该分析一下猫的皮毛应该有什么纹理、什么色彩,猫的眼睛是什么颜色,猫的耳朵是什么形状,猫的胡子多长,把这些总结成规则,然后靠这些规则去判断图片中是否含有猫。
但事实上这些是非常困难的。我们刚才看到了,猫的皮毛颜色有非常多的变化,猫的胡子的长度可能可以比较准确地测量,但当图片拍摄的远近发生变化时,图片中猫的胡子的长度也会发生很大变化。
后面我们就想,我们是怎么教孩子识别猫的?我们会不会在家里对孩子说,你可记清楚了,胡子这么长的是猫,如果再长两厘米,它就不是猫了。我想没有家长会这样教,其实我们就是给孩子看了很多猫的照片,孩子就熟悉了猫的概念。

后来我们就把这个方法推广到让机器去学习猫的概念,这就是机器学习的方法。我们会收集非常大量的关于一个物体的资料,这里是关于猫的照片,然后我们把这些猫的照片放到计算机里,用机器学习、统计学习或者是深度学习的模型,让计算机不断地分析、理解这些图片,然后识别猫的概念。
真的有人这么做了,2012年,谷歌很兴奋地宣布,他们发布了一个能够识别猫的计算机算法。他们从YouTube上收集了1000万张图片,然后用了16000个CPU的核,他们让这16000个核反反复复地看这1000万张图像,看了一个星期的时间,最后他们很兴奋地宣布,我们的计算机能够识别猫了。

左边给出的就是被这个算法判断为猫的例子,其实仔细看就会发现里面还是有些错误的,右边是这些图片的平均照片,确实这个算法识别出的大部分都像猫,也确实是猫的照片。
当然作为一个计算机视觉的研究者,我所要做的绝对不是识别猫这么简单。我们知道图像中有各种各样的物体,有人、车、建筑物,有人造物体、自然界的物体,有动物、植物,这些都是我们识别的对象。

对于计算机视觉来讲,我们还要应对的一个很大的挑战,就是这些对象中包括非常复杂的变化,这种变化可能来自于光照、姿态,也可能来自于其它各种各样形变的因素。而且图像、视频的数据量很大,内容很丰富,这就要求我们的系统具有非常高的处理效率,这些就构成了技术者研究过程中的挑战。

我经常用这幅图来比喻我们的任务,这座山的顶峰是我们的目标,就是要建立和人类匹配,甚至超过人类的超级视觉能力。我的目的就是登上这座山的顶峰,遗憾的是在很长的时间里,比如在2011年,我感觉我只能在山脚到处寻找,离山顶非常之远,那时候我们只能通过一些方法很局部、很微弱地推动技术的进步。
当时我跟我的学生讲,我们做计算机视觉的研究是非常安全的。当然这个安全可能有一些贬义词的部分,就是说有可能在我的有生之年,我们这个研究的很多问题都不会得到有效的解决。我们今年提一个百分点,明年再招一个博士生,再提高两个百分点,就这样做下去,直到我退休。
这样想想总是觉得有点落寞,事实上后面情况发生了很大的变化,一个重大的变化就是以卷积神经网络为代表的深度学习方法引入到计算机视觉,我们终于找到了一条能够快速登山的爬山道,所以大家可以看到计算机视觉中的很多技术取得了日新月异的进步,在人脸识别、物体识别等任务上,计算机的能力在特定数据库上甚至可以超越人。
爬到这儿的时候,我愈发地意识到这座山后面的部分可能更难爬。爬山道在哪我们现在也不清楚,但作为一个研究者,我的职责就是从这看不清的云雾中间去找到一条可行的道路来解决这些问题。那么下面我就分享爬山中间的一个工作,人脸识别和人脸检测。
这项技术大家应该很熟悉,我们现在可以刷脸支付、刷脸解锁手机,我们通过海关的时候也会有人脸识别的一些程序判断是不是你本人。这里面大概可以分成两个任务,一个任务是人脸识别,一个是人脸比对。人脸比对的任务就是给出两张照片,判断是不是同一个人。人脸识别就是给出一张照片,去判断很多张照片中的哪张照片和这个照片是同一个人的。

很显然,第一个任务更容易,1:1,随便猜正确率也有50%。如果第二个任务给出的照片是一千张,随便猜是1/1000。如果是整个上海2000万人口的照片,那随便猜的正确率是2000万分之一。
人脸识别的流程是怎样的呢?我们会先把照片中人脸的区域找出来,这个工作叫做人脸检测,就是发现人脸。找到人脸之后,我们会通过一些计算机的算法,通过一些计算机的模型,比如深度学习的模型,去发现这些照片中与人脸相关的最有鉴别性的特征。比如说我们眼睛的形状、鼻子的形状,我们的脸型,脸部器官的组合都会成为有用的特征。
通过计算机的算法提取这些特征之后,我们会把这些特征存起来,数据库中的照片我们也会进行特征的检测和提取,最后我们把两个特征进行匹配。比较像的,我们就认为照片中是同一个人,不像的就认为不是同一个人。

这是我们的算法在人脸检测中所做的效果,我们可以看到现在的算法对于不同的肤色、不同的表情以及人脸姿态的变化,都有非常强的鲁棒性。我们的算法不仅能够找到人脸,还能同时发现你的眼睛、鼻子、嘴角的位置。可能有人会问,发现这个有什么意义吗?
其实蛮有意义的,我想很多女士都喜欢用美颜相机,其实在美颜相机做的第一件事情就是发现你的眼睛在什么位置,鼻子在什么位置,它会针对不同区域采用不同的美化算法。不然的话,我们把美白的方法用在眼睛上,就不好看了。

大家能不能猜一下,这张照片中有多少张人脸?计算机发现了接近800张人脸,而且这件事情可以做得非常快,只需要不到一秒钟的时间。把照片送进计算机,它就会把人脸的数目和圈中人脸位置的框输出出来。找出人脸之后,我们就要进行人脸识别。

大家认为这两张照片是不是同一个人呢?回答是或者不是的都有,这其实是同一个人。

这两张照片像不像同一个人呢?好像是又好像不是,事实上这两种照片不是同一个人。

那这两张呢?我看大家觉得不是的比较多,实际上这两张是同一个人。
我们的人脸确实太多变了。我现在40多岁,十多年前我刚好回国。前段时间我在整理照片,把十多年前的照片整理出来,结果发现岁月真是一把杀猪刀,当然对女士除外。

这两张大家应该都知道不是同一个人,但看起来确实蛮像的。

为什么人脸识别具有挑战性呢?因为对于同一个人,随着他的年龄、表情、包括妆容的变化,他的相貌都会发生很大的变化。对于不同的人,地球上有六七十亿的人口,即使在上海的2000万人口中,你也很容易发现一个和你长的很相像的一个人。这就是人脸识别的挑战。顺便说一下,刚才我给大家看的这些照片,让计算机去做识别,都没有任何问题。

除了人自身的变化之外,还有一种情况,是有时候人脸的照片特别模糊,比如说我们照相的时候手抖动了,或者是离的比较远,往往会有这样模糊的照片。可能这两张照片大家顶多只能看出来是女性,看不清内容,我们就可以用计算机算法把它变得更清楚一点,就像右边的这些照片。
现在人脸的识别技术到底到了一个什么层次呢?我刚才说过,人脸识别有两个任务,一个是1:1的比对,一个是1:N的识别。我们先看1:1的比对。1:1的比对往往用在一些门禁和海关系统。所以我们首先要保证的是,它一定不能让一个人与照片不符时通关,比如说我拿着张三的身份证一定是不能通过的。就是说在一个很大的数据集上,你的误识率要非常低,然后再是识别的精度。

2014年的时候,我们可以做到10的4次方的数据集,也就是上万人。慢慢到10的5次方、10的6次方,到我们做这个实验的时候,已经可以保证在千万级的数据集上,达到99%的识别率。这些有什么意义?我讲一些应用场景来说明。
深圳湾和香港相邻的地方有一个深圳湾口岸,是中国最大的单个的海关通关口岸之一,每天大概有6万人通过。在2014年的技术水平下,用这个技术,大概每三个小时会错判一次,就是说每三个小时就可能有人用假证件混过去一次。在2015年的技术水平下,每两天会错判一次。到2016年的时候,,可能一个月这个系统才会错判一次。到2018年,采用我们最新的技术,大概半年才会错判一次。
所以大家听完这次演讲,要记住千万不要带假证件去闯海关,因为现在这个系统判错的几率已经低于买彩票的中率了,与其去办这样的事情,不如多去买两张彩票。
刚才说了,1:N的识别更难,因为需要从N个人员中找出哪些照片是给定的这个人。在2013年,我们可能在数百人中能识别出正确的给定对象,到2018年能够达到这个数千万人的层次,这背后实际上是技术快速的发展、方法快速的进步。

我们也可以体会一下这个技术的应用范围。2013年的时候,可能就应用在一个几百人的小公司,每天员工打一次卡,可以保证没有什么错误。到2015年,可以做到上万人,比如上海的陆家嘴街道大概有十几万人的户籍人口,在这个范围内也有比较好的识别率。到2016、2017年的时候,我们已经可以处理一个拥有几百万人口的比较大的区。
到2018年,我们最新的技术到达了千万级别,我们知道上海大概有2000多万人口,是中国乃至世界上最大的城市之一,这时候我给计算机一张照片,计算机就能从2000万人中找出来是谁。可以想象一下,这个任务对人来讲是几乎没有可能的,没有人会认识上海市的2000万人,更没有人能宣称自己可以记住上海市的2000万张人脸。但我们的计算机系统确实已经具备这样的能力了。

我们的课题组在这里面有很多些原创性的方法在国际上有最顶级的论文发表,也被大量的引用。我们参加过一些国际竞赛,MegaFace是美国华盛顿大学组织一个国际竞赛,我们在FGNet跨年龄任务之上仅次于谷歌,排在第二位。事实上谷歌用了2亿的训练数据,我们只有几百万。
同样我们的技术也跟一些企业合作,像南京地铁的大规模人脸识别,还有一些智能的服务摄像头等应用。除了人脸识别,我们还做很多事情,包括从视频中去识别人的行为,在这件事情上,我们的很多技术也在像商汤科技这样的大型企业得到了比较广泛的应用。

我们还有一项技术是从场景中够检测和识别文字,大家现在经常去海外,去美国、英国可能还好一点,比如说去俄罗斯或者是韩国,可能我们会看不懂路牌、看不懂菜单,这时候你只要拿手机拍一下,它就会自动把这些文字检测识别,并翻译出来。实际上在这项技术上我们也与达成了华为合作,已经应用到了华为的下一代智能手机中去。
我们还与医院合作,做青光眼的辅助诊断的识别。我们还把这些技术应用到了水下,让水下的图像变得更清晰,让计算机能够识别水下的浮游生物、鱼等对象。我们课题组做了很多成果,如果大家有兴趣,可以去我们的主页看一下。
在过去的几年里,我们也参加了计算机视觉领域的一些知名的国际竞赛,取得了多次第一,为此我们的学生也付出了巨大的努力。我想在这个领域,我们中国确确实实是在世界第一集团,我们和世界最领先的技术并没有有明显的差距。这也是我们中国现在要重视发展人工智能技术的一个重要的原因。
新闻排行
图文播报
科普信息网 - 科普类网站
联系邮箱:85 572 98@qq.com 备案号: 粤ICP备18023326号-39
版权所有:科普信息网 www.kepu365.cn copyright © 2018 - 2020
科普信息网版权所有 本站点信息未经允许不得复制或镜像,违者将被追究法律责任!